
2.1 BFT协议概述
一个分布式系统是由多个节点组成,节点之间需要网络发送消息通信,根据它们遵循的协议在某个任务消息达成共识并一致执行。这个过程中会出现很多类型的错误,但它们基本上可以分为两大类。
- 第一类错误是节点崩溃、网络故障、丢包等,这种错误类型的节点是没有恶意的,属于非拜占庭错误。
- 第二类错误是节点可能是恶意的,不遵守协议规则。例如验证者节点可以延迟或拒绝网络中的消息、领导者可以提出无效块、或者节点可以向不同的对等体发送不同的消息。在最坏的情况下,恶意节点可能会相互协作。这些被称为拜占庭错误。
考虑到这两种错误,我们希望系统始终能够保持两个属性:安全性(safety)和活跃性(liveness)。
- 安全性:在以上两类错误发生时,共识系统不能产生错误的结果。在区块链的语义下,指的是不会产生双重花费和分叉。
- 活跃性:系统一直能持续产生提交,在区块链的语义下,指的是共识会持续进行,不会卡住。假如一个区块链系统的共识卡在了某个高度,那么新的交易是没有回应的,也就是不满足liveness。
BFT(拜占庭容错协议)是一种即使系统中存在恶意节点也能保证分布式系统的安全性和活跃性的协议。根据Lamport[2]的经典论文,所有BFT协议都有一个基本假设:节点总数大于 3f 时,恶意节点最大为 f ,诚实节点可以达成一致的正确结果。
2.2 PBFT
实用拜占庭容错算法(PBFT[3])是现实世界里首批能够同时处理第一类和第二类错误的拜占庭容错协议之一,基于部分同步模型,解决了之前BFT类算法效率不高的问题,将算法复杂度由节点数的指数级降低到节点数的平方级,使得拜占庭容错算法在实际系统应用中变得可行。
目前区块链中使用的BFT类共识协议都可以认为是PBFT的变形,与PBFT一脉相承。
2.2.1 正常流程
PBFT正常流程如下所示(图1中C为客户端,系统中有编号分别为0~3的四个节点,且节点3为拜占庭节点):
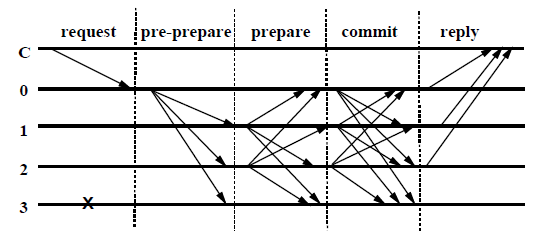
图1 PBFT正常流程 PBFT 正常流程为3阶段协议: - pre-prepare:主节点(Primary)广播预准备消息(Preprepare)到各副本节点(Replica) - prepare:该阶段是各个节点告诉其他节点我已经知道了这个消息,一旦某个节点收到了 包含n-f 个prepare消息(我们将使用QC也就是Quorum Certificate来指代,下同)则进入prepared状态 - commit:该阶段是各个节点以及知道其他节点知道了这个消息,一旦某个节点收到了n-f 个commit消息(QC)则进入committed状态
2.2.2 视图切换流程
视图切换(viewchange)是PBFT最为关键的设计,当主节点挂了(超时无响应)或者副本节点集体认为主节点是问题节点时,就会触发ViewChange事件,开始viewchange阶段。此时,系统中的节点会广播视图切换请求,当某个节点收到足够多的视图切换请求后会发送视图切换确认给新的主节点。当新的主节点收到足够多的视图切换确认后开始下一视图,每个视图切换请求都要包含该节点达到prepared状态序号的消息。
在视图切换过程中,我们需要确保提交的消息序号在整个视图更改中也是一致的。简单来说,当一个消息定序为n,且收到2f+1个prepare 消息之后,在下个视图中,依然会被分配序号为n,并重新开始正常流程。
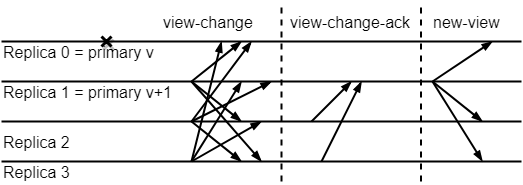
图2 PBFT视图切换流程 如图2所示,viewchange会有三个阶段,分别是view-change,view-change-ack和new-view阶段。从节点认为主节点有问题时,会向其它节点发送view-change消息,当前存活的节点编号最小的节点将成为新的主节点。当新的主节点收到2f个其它节点的view-change消息,则证明有足够多人的节点认为主节点有问题,于是就会向其它节点广播。
2.2.3 通信复杂度问题
PBFT 是基于三阶段投票即可达成共识的协议。prepare和commit阶段中,都需要每个节点广播自己的prepare或commit消息,因此通信复杂度是$O(n^2)$。
view change过程中,需要所有的副本节点先time out,然后对于view change这件事达成共识,然后,他们把这个共识(以及已经达成了共识这件事)告诉新的主节点,新的主节点还要把这个消息广播出去宣布view change,因此,view change的通信复杂度是$O(n^3)$。
高达 O(n^3) 的通信复杂度无疑给PBFT 的共识效率带来了严重的影响,极大地制约了PBFT的可扩展性。
2.3 BFT协议的优化
如何把$O(n^3)$的通信复杂度降到$O(n)$,提高共识效率,是BFT共识协议在区块链场景中面临的挑战。针对BFT共识效率的优化方法,具有以下几类:
2.3.1 聚合签名
E.Kokoris-Kogias等在其论文中提出了在共识机制中使用聚合签名的方法。论文中提到的 ByzCoin [4]以数字签名方式替代原有PBFT使用的MAC将通信延迟从$O(n^2)$降低至$O(n)$,使用聚合签名方式将通信复杂度进一步降低至$O(logn)$。但ByzCoin在主节点作恶或33%容错等方面仍有局限。
之后一些公链项目,例如 Zilliqa [5]等基于这种思想,采用EC-Schnorr多签算法提高PBFT过程中Prepare和Commit阶段的消息传递效率。
2.3.2 通信机制优化
PBFT使用多对多(all-to-all)的消息模式,因此需要 O(n^2) 的通信复杂度。
SBFT(Scale optimized PBFT)[6]提出了一个使用收集器(collector)的线性通信模式。这种模式下不再将消息发给每一个副本节点,而是发给收集器,然后再由收集器广播给所有副本节点,同时通过使用门限签名(threshold signatures)可以将消息长度从线性降低到常数,从而总的开销降低到$O(n^2)$。
Tendermint[7]使用gossip通信机制,乐观情况下可以将通信复杂度降低到$O(nlogn)$。
2.3.3 view-change流程优化
所有的BFT协议都通过view-change来更换主节点。PBFT,SBFT等协议具有独立的view-change流程,当主节点出问题后才触发。而在Tendermint、HostStuff[8]等协议中没有显式的view-change流程,view-change流程合入正常流程中,因此提高了view-change的效率,将view-change的通信复杂度降低。
Tendermint 将roundchange(和viewchange类似)合入正常流程中,因此roundchange和正常的区块消息commit流程一样,不像PBFT一样有单独的viewchange流程,因此通信复杂度也就降为$O(n^2)$。
HotStuff参考Tendermint,也将视图切换流程和正常流程进行合并,即不再有单独的视图切换流程。通过引入二阶段投票锁定区块,并采用leader节点集合BLS聚合签名的方式,将视图切换的通信复杂度降低到了$O(n)$。
2.3.4 链式BFT
传统BFT需要对每个区块进行两轮共识,$O(n)$的通信复杂度可以让区块达到prepareQC,但是必须要$O(n^2)$ 的通信复杂度才能让区块达到commitQC。
Hotstuff将传统BFT的两轮的同步BFT改为三轮的链式BFT,没有明确的prepare,commit共识阶段,每个区块只需要进行一轮QC,后一个区块的 prepare 阶段为前一个区块的 pre-commit 阶段,后一个区块的 pre-commit 阶段为前一个区块的 commit 阶段。每次出块的时候都只需要$O(n)$的通信复杂度,通过两轮的$O(n)$通信复杂度,达到了之前$O(n^2)$的效果。
2.3.5 流水线(Pipelining)和并行处理(Concurrency)
PBFT、Tendermint等协议具有即时确定(Instant Finality)的特性,几乎不可能出现分叉。在PBFT中,每个区块被确认后才能出下一个区块,Tendermint还提出区块锁定的概念,进一步确保了区块的即时确定性,即在某个round阶段,节点对区块消息投了pre-commit票,则在下一个round中,该节点也只能给该区块消息投pre-commit票,除非收到新proposer的针对某个区块消息的解锁证明。
这类BFT共识协议本质上是一个同步系统,将区块的生产和确认紧密耦合,一个区块确认后才能生产下一个区块,需要在块与块间等待最大的可能网络延迟,共识效率受到很大的限制。
HotStuff的Pipelining方法将区块的生产和确认分离,每个区块的最终确认需要后两个区块达到QC,也就意味着上一个区块没有完全确认(需要满足Three-Chain)的情况下可以生产下一个区块。这种方式实际上还是一个半同步系统,每个区块的产生还是需要等上一个区块达到QC。
EOS[9]的BFT-DPoS共识协议可认为是一种完全并行的Pipelining方案:每个区块生产后立即全网广播,区块生产者一边等待 0.5 秒生产下一个区块,一边接收其他见证人对于上一个区块的确认结果,使用BFT协议达成共识,新区块的生产和旧区块确认的接收同时进行,这极大地优化了出块效率。