
在PlatON技术白皮书前两部分发出的第三天,本着学英语和学技术的出发点,在有道词典的帮助下,认真学习了白皮书,首先持肯定的态度,白皮书整体表达的思路很清晰,意思也很明确,总之就是要通过区块链和隐私计算技术的结合,让人工智能这项旧时王谢堂前燕,飞入寻常百姓家。我也认可这个理念和路径。
当然了,目前白皮书只发了前两部分,后面的部分应该写完初稿不过还在修订,会对系统架构进行拆解,我了解了一下,发现系统架构和技术路径也更清晰了,相比1.0的白皮书更具象了,说明目前的开发应该是取得了实质性的进展了,此次就先不展开了。
今天这里的主要目的,是在阅读过程中,发现一些小问题,有些很确定是作者的笔误,有的可能是我理解上的不一致,特整理发布如下,希望探讨交流。
1. 数据源问题
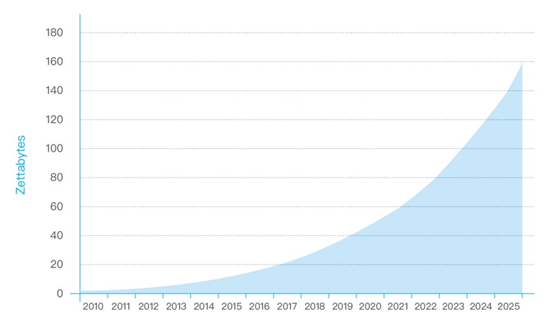
第一章节第二段中,对未来的数据量进行了预测,引用的是IDC的报告,原文是“ IDC forecasts that by 2025 the global data will grow to 163 zettabytes (that is a trillion gigabytes).”
我核实了一下,参考的报告应该是2017年5月发布的《数据时代2025》,事实上2018年的时候,IDC更新了这份报告,将对2025的年数据总量预测从163ZB提升到了175ZB,虽然站在未来的角度,差距不大,不过还是建议用新不用旧。
2. 图文不一致问题
上一个问题提到,引用IDC的预测数据,2025年数据总量是163ZB,不过相应的配图中(如下)可以很明显的看到,2025年的数据明显没有超过160。建议核实原报告。
3. 用词准确性问题
依然接上一个问题,为了体现数据的高增长速率,文中将2025年的数据总量和2016年的进行了对比,原文是“That’s ten times the 16.1ZB of data generated in 2016”,这里用的词是“generated in 2016”,如果直观理解的话,是2016年(这一年)产生的数据,但是事实上原报告的意思应该是截至2016年的数据总量,所以,以我仅剩不多的高中语法知识,这里是否把in 改为up to或者by更不容易引起歧义.
事实上,这段开篇第一句也是这么用的,“the number of connected devices worldwide is expected to reach 30.9 billion by 2025”,这里可能是一时疏忽吧。
4. 图中元素的缺少
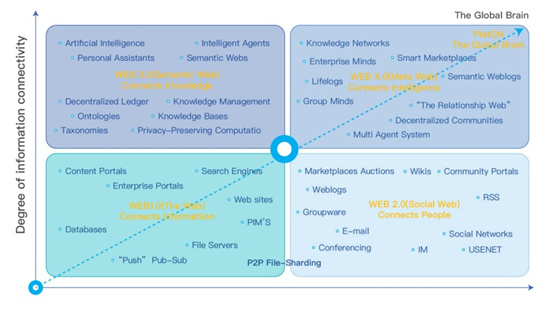
这幅图应该是在之前的简版的PPT中出现了,通过笛卡尔坐标系的方式来表面WEB的进化方向,纵轴表示的是“Degree of imformation connectivity”,横轴是“Degree of social connectivity”,不过这里,横坐标的标注没了,估计应该是不小心漏了?
5. 图中和理解不一致的地方
这个问题接上一张图,记得我应该在上一篇帖子中提到,我个人觉得Web3.0的位置不应该是这样的。
从图的表现形式上来看,WEB3.0看起来和WEB 2.0一样,更像WEB1.0的分支,而不是2.0的进化,WEB3.0在信息联系程度上加强了,但是在社交联系程度上没有进步,而WEB2.0则正好相反。
如果只是这样,我觉得问题也不大,因为Web3.0到底是什么,现在本身也没有权威的定义。
但是文中后面对Web3.0又给出了自己对Web3.0的理解,其中提到:
Ubiquitous Connectivity, connect anyone, anywhere, anytime to anything that is open, trustless, and permissionless.
anyone,任何人;anything任何事;anytime、anywhere,任何时间任何地点,这么泛在的链接程度,Degree of social connectivity反而还不如Web2.0,确实有些难以接受。
如果横轴是Degree of social emotion,我个人都会好理解一些。毕竟可以说是人工智能带来了硅基生命的高光时刻,在一定程度上掩盖了碳基生命的情感涌现。
6. 图的笔误
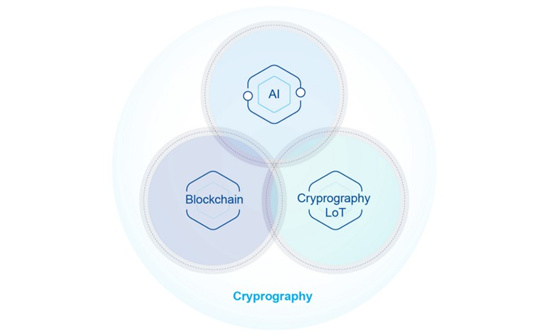
Web3.0的驱动是区块链、人工智能、物联网,但是配图上本来应该是物联网的位置写的Cryprography,查无此词,我想应该是想写Cryptography(密码学吧),包括下面大圈里写的,Cryrography,同样查无此词,笔误吧。
还有物联网的简写IoT,LoT应该也是笔误。
7. 重复引述问题
为了表面数据增长对市场的影响,文中多次引述了权威的调研报告,本身这也不是问题,不过从写文章的角度,个人角度还是有些多了,比如前文说2025年数据将达到多少( by 2025 the global data will grow to 163 zettabytes ),后面在论述的时候又提及2020年数据总量将达到多少(According to IDC estimates, the global data volume is expected to reach 44 ZB in 2020)。
一方面,既然以2025的数据为参照基础,前后保持一致是不是会更好,突然又参照到2020年的数据,是有什么特殊考虑吗?
另一方面,IDC写这篇报告的时候还没有到2020年,所以他是预测,而我们引述的当下,已经是2021年了,再用这个预测是不是就不太合适了。
综上,为何不都有2025年的数据呢。
此外,文中还有很多引用的数据,建议若无特殊目的,可以都以同样的年份作为参照。
8. 系统架构图问题
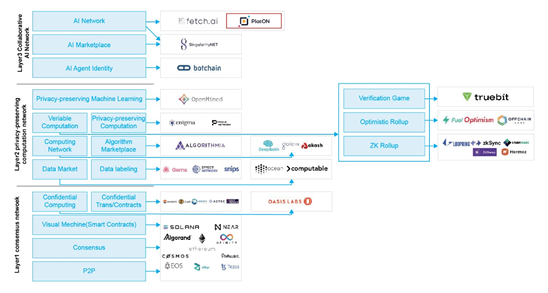
这个问题可能提的不太成熟,不过我还是试着理解并问一下,在这幅图中,分别讲述了三层网络和他们的代表,PlatON所属的位置是第三层,那么按照逻辑来说,意思就是说第三层天然包含了第二层,第二层天然又包含了第一层。
那么有三个疑问,
第一就是图不是很直观的能表达出这种包含和依赖关系;
第二就是,我个人的逻辑理解里面,这三层不一定是包含的关系,事实上,应该是相互有一定独立性的,比如隐私计算网络,严格来说不一定是需要区块链和共识的,当然了,这个本身是和我们的描述范围和定义相关的,只要在图外定义和描述清楚我们的范式即可;
第三就是,如果在我们定义的范式下,即三层网络是依次依赖包含的,那么Oasis应该是放在第二层,据我了解,它也是做隐私计算的。
9. 关于TEE是链上还是链下的问题
文中将基于TEE的隐私计算定义为共识层,即链上,原文“There are three main ways to implement privacy-preserving computation protocols on Layer1: a confidential computing scheme using TEE,”
我个人的理解中,TEE应该不是属于链上的,TEE中发生的计算是独立的,被硬件(及背后的硬件制造商)所置信的,TEE的身份和验证信息是置于链上的,是达成共识并且可追溯的,但是TEE中本身执行的计算其实链上是无法知悉和验证的,刚才说了,计算的可信性是由TEE这个硬件保证的,而这个硬件是由制造商保证的,比如intel,把通过TEE实现的隐私计算归结为共识层,是否不是很恰当。