
硬间隔支持向量机
支持向量机很早很早就被提出来了,而且在最近几年里一直在被更新和改进,但是追本溯源,我们还是得回到那个古老的年代,去看看支持向量机原本的模样。
我们总是希望这世界上的事情没有那么多的弯弯绕绕,能一刀切开就好了。SVM 最早干的就是这一刀切的工作。现在有两拨样本,标签分别是 {-1,+1},它们在原空间上的分布如下图所示:
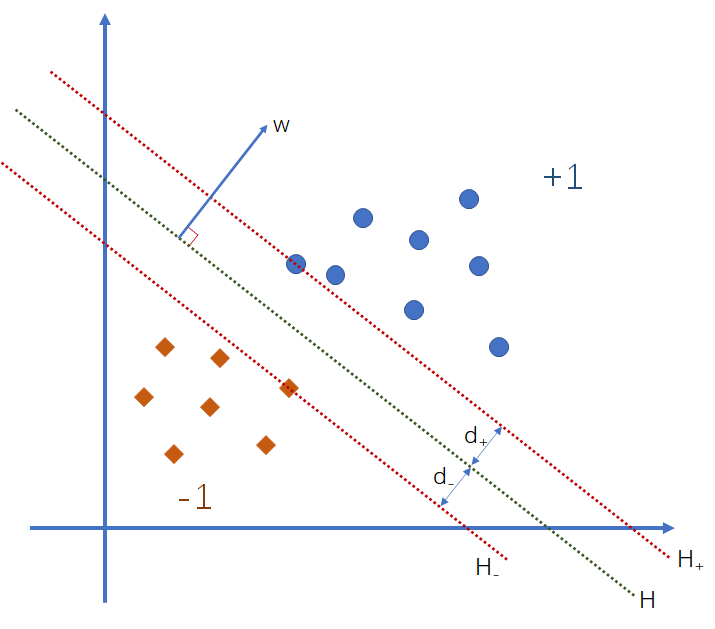
我们希望能够找到一条分界线,把两拨样本合理地分开,而且尽可能地让最靠近分解的样本点之间的距离最大,也就是图中的 d+ 与 d- 之和要最大。当我们确定分界线之后,无论类别是什么,我们取最靠近分界线的样本点,做穿过该样本点且与分界线平行的直线,称之为边界线,两个类别的边界线距离就是间隔(Margin)。我们给图中的线 H 定义一个方程,即:
![]()
而 H+ 和 H- 则分别是
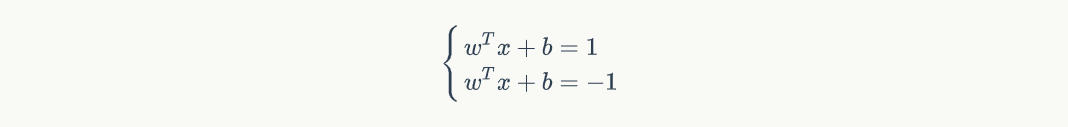
我们合并这两个边界线的方程,即:

那我们会开始思考,既然我是想要让间隔最大,那我应该考虑间隔是什么,于是这里就要用到高中学的一个知识点——两直线间的距离公式:
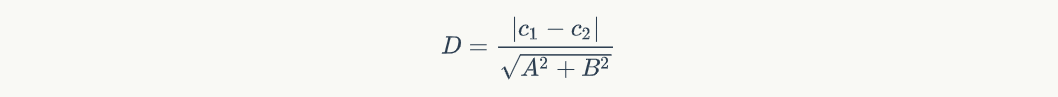
由于 H- 到 H 的距离和 H+ 到 H 的距离势必要相等的,因此间隔就是:
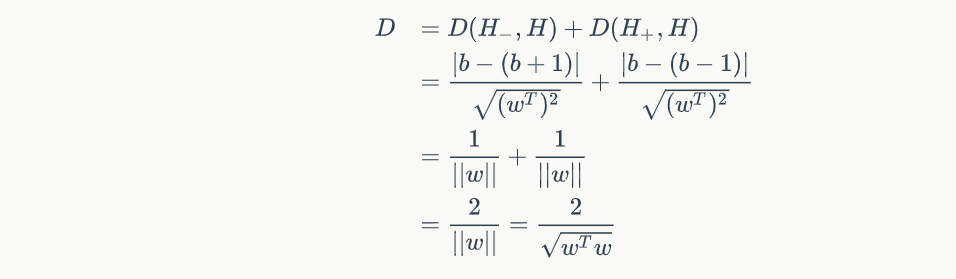
在上式中,我们能发现如果希望 D 越大,那必须让 wTw 越小,因此这就转换成一个最优化问题,求的是 wTw 的最小值,当然还有一个限制条件,就是要限制样本点不能出现在间隔当中,只能是在间隔边上或者间隔外,即:
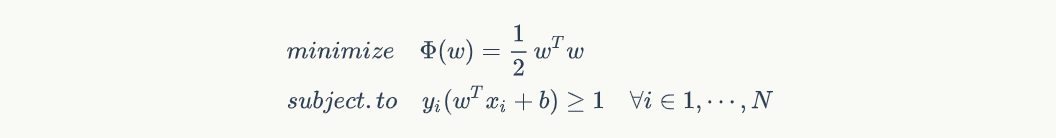
接着我们得构造 Φ(w) 的拉格朗日多项式,要先做个说明的是,为什么是减号,而不是加号:
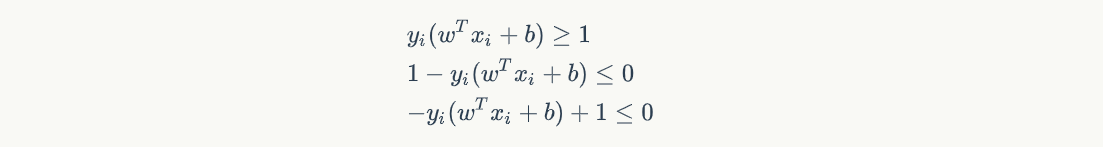
说明结束,转换成拉格朗日多项式就是
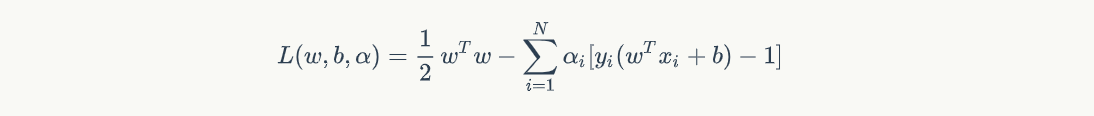
接着对 w 和 b 做微分:
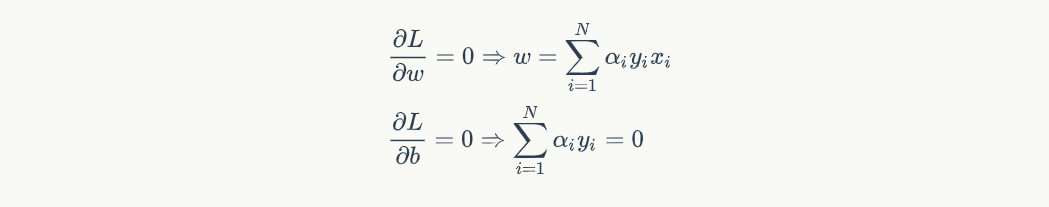
那这样子我们就能求出在原空间中的 L(w,b,α) 是个啥了。将拉格朗日多项式的微分所得带回 L 中,但我们可以先算 wTw 和 wTxi 即:
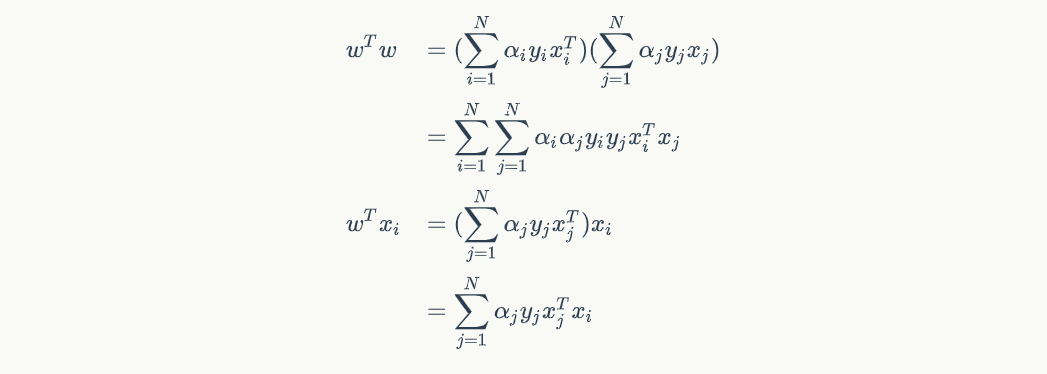
接着我们把上面两结果带进 L(w,b,α) 里,可得:
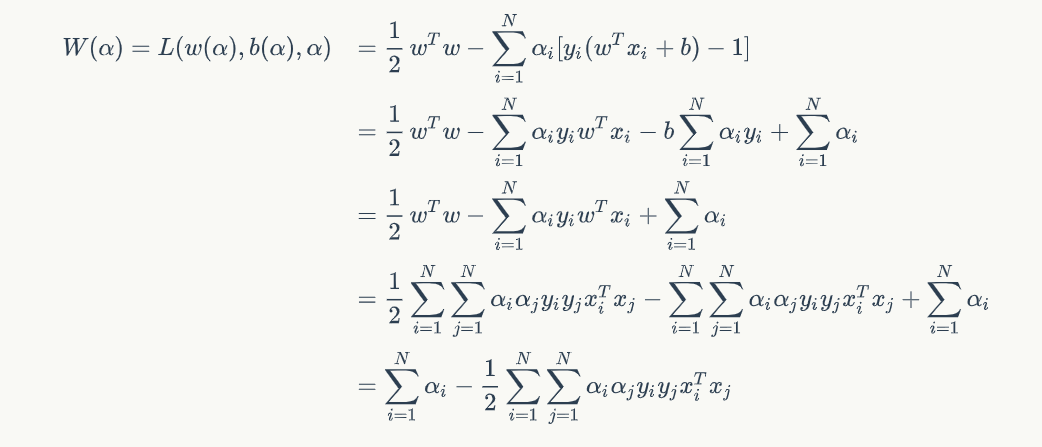
到这里,我们可算是把 W(α) 给整出来了,于是乎我们就转换成了一个对偶问题,来求 W(α) 的最大值,但是要记得它有俩限制式:
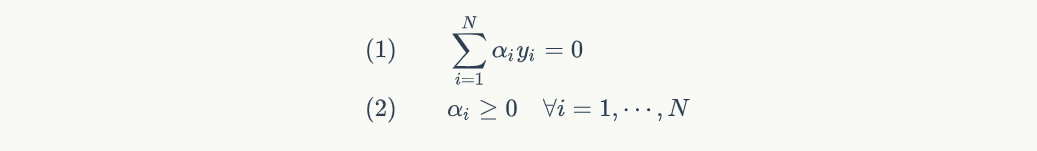
到这里,我们对于原空间的推导就结束了,因为我们的主要目的是把它映射到高维空间去,也就是把全部的 xi 都换成 φ(xi),推导过程和在原空间时是一致的,只不过是把 wTxi 换成了 wTφ(xi),即:
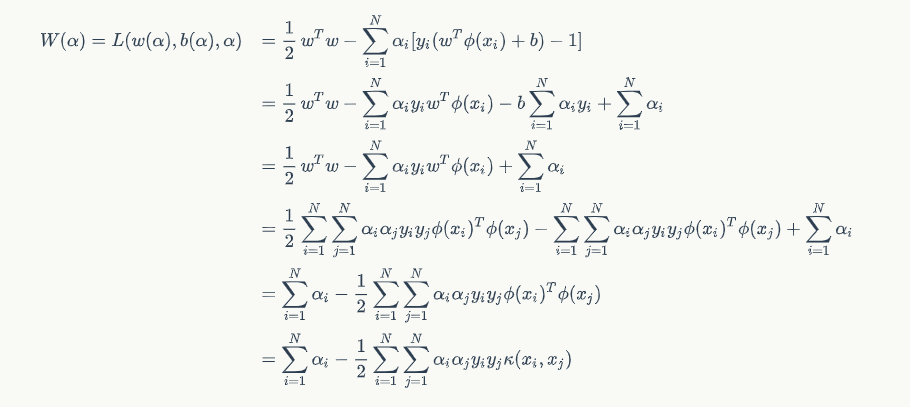

于是我们就能确定:
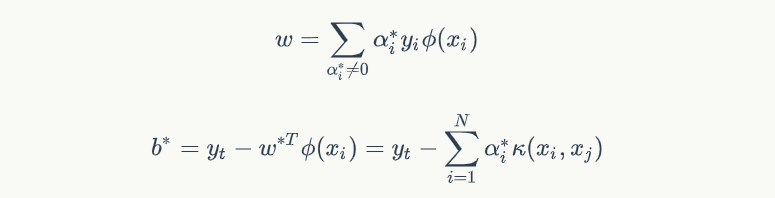
最终得到最后的分界线方程就是:
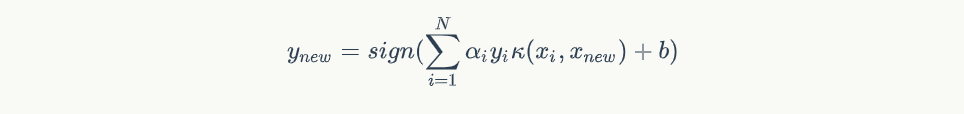
因为论坛不支持LaTex编辑,所以所有的公式均为截图,我也觉得好南啊!如果需要看完整的内容的,可以到我的博客链接来,在这里:
其中还有关于软间隔的部分,欢迎踢踢