
尊敬的节点合作伙伴,尊敬的社区成员,大家好,
自3月9日我们的测试网络出现故障停止出块以来,我们得到了来自大家的最温暖的鼓励和最热忱的帮助。 整个升级修复的过程都是在广大节点合作伙伴和社区成员的帮助下,一步一步攻克难关而最终取得胜利的。
你们就像那守卫着我们共同家园的守夜人,永远都是我们最值得依赖的伙伴,我们要向你们致以最为诚挚的感谢,谢谢你们!
我们必须一五一十地把这两天时间里发生的点点滴滴都如实记录下来,作为PlatON网络进一步全面社区化的重大里程碑,烙印在我们成长的道路之上。
3月9日上午6时56分
网络出现故障后,Bit Cat、节点易、Wetez等节点合作伙伴在沟通群中第一时间就向我们提供异常情况的完整日志,Cobo也及时为我们提供了报错信息,这为故障的排查和定位节约了大量时间。
3月9日下午13时59分
我们向社区发布了此次故障的初步排查原因是“某些治理相关的异常场景导致个别节点状态出现异常,在101个备选节点选举的时候触发出块异常导致停止出块。”同时也提出了通过社区化流程来进行治理升级,这一提议得到了社区的一致赞同。
3月9日晚上19时36分
我们向社区提出了此次故障的详细原因是“由于某些验证节点储存在链上的状态数据有异常,导致了在epoch切换时选举下一epoch的备选节点时,出块逻辑无法正常执行,导致无法正常生产和验证区块。”
同时,我们向社区详细介绍了升级操作的风险,以及基于这些风险评估而拟定的升级方案——确定一个时间段,没有参与当前共识轮的验证节点先升级完成,然后通过脚本定时统一升级的方式,让当前共识轮的验证节点一起升级。
节点合作伙伴对方案设计提出大量建议……
3月10日上午11时22分
就停止出块时25个节点脚本升级和25个节点之外的节点升级启动的时间,在节点微信群中启动投票,多数节点代表第一时间予以响应。
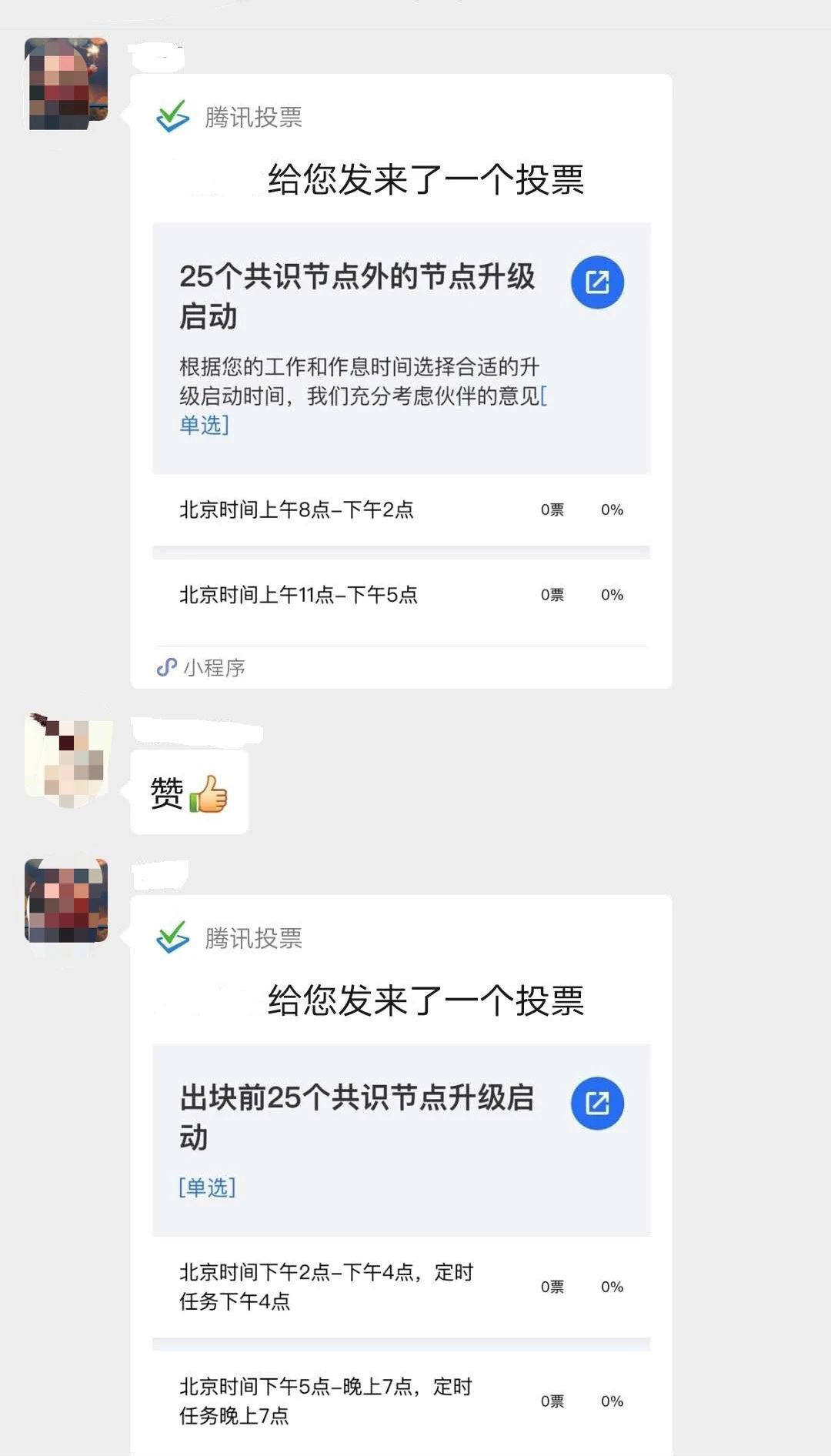
3月10日下午18时16分
投票结束。
停止出块时的25个节点定时启动时间投票:北京时间下午2点到4点,27票;北京时间晚上5点到7点,3票。少数服从多数决定投票结果:停止出块前的25个节点升级启动时间为下午2点到4点。
25个节点之外的节点升级启动时间投票:北京时间上午8点到下午2点,15票;北京时间上午11点到下午5点,12票。少数服从多数决定投票结果:25个节点之外的节点升级启动时间为上午8点到下午2点。
同时,向节点发送0.10.1版本节点升级操作指南和停止出块前25个节点定时启动脚本,广泛征集社区意见。
节点合作伙伴对具体执行方案再次提出了大量的意见建议……
3月10日晚上22时07分
收集到节点合作伙伴各类型反馈意见共计15条,并一一进行了回复。
Blockpool的小伙伴不无担心地表示:“我想问一下脚本的作者在群里面?估计第一次被这么多人review吧(憨笑脸)”,PlatGo的小伙伴敢于下判断:“就算在群里,估计也早就不敢说话了。”
对此,我们的社区负责人在群中表现得非常镇定:“不要客气,请大家猛烈开火(机智脸)”首席架构师在这时也冒头了:“大家有问题尽管提哈,环境太复杂了,脚本不好写啊(流泪)”旁边不缺补刀的:“第一次看到看到升林总用(流泪)这个表情”。
节点合作伙伴对具体执行方案继续提出了大量的意见建议……
3月11日凌晨3时17分
采纳了社区反馈的多达六项意见建议的脚本最终完成,脚本作者发送了升级操作指南以及脚本下载链接邮件。
3月11日上午8时02分
向全部节点合作伙伴提供升级操作指南,25个节点之外的节点开始陆续升级。
升级过程中还有很多朋友就具体操作提出了不少问题和意见反馈,我们都一一进行了记录。
3月11日下午14时
停止出块时25个节点开始陆续运行脚本,脚本将在16点准时同时启动,以保障大家同时进行升级,不能让一个节点被抛下。

3月11日下午16时
25个脚本陆续启动。
好像网络没有启动起来……
内部工作群马上开始安排找日志排查原因。
当时得知的情况是:从拿到的两个验证节点的日志来看,每个节点的view差异较大并且没有同步,所以各自出的块彼此不认,互不签名。
3月11日下午16时38分41秒
网络开始出块。
节点群中一片欢腾。
这是在那38分钟里发生的故事:
“在网络停止出块的时间段内,部分验证节点进程退出不在线,这部分验证节点的view number停止增长。但是由于没有正常出块,保持在线的验证节点持续切换view,其view number一直增长。最终导致不在线的验证节点和持续在线的验证节点之间的view number差距逐渐拉大,到北京时间3月11日下午16:00时,这个差距拉大到2000多,此时由于大部分验证节点之间的view不齐,导致不能出块。而在没有新区块产生的时候,验证节点需要逐个同步view,每个view的超时时间是40秒,这个时间也是view的同步时间,因此最终等了近40分钟网络中才达到至少18个节点同步到相同的view,这时才恢复出块。”
写在最后
至此,PlatON测试网络完成了一次由社区全程参与并作出了大量贡献的提案升级。
再次对所有参与这次治理升级过程的,耐心支持和热情帮助我们的云图守夜人真诚致谢,没有你们,这次的升级不会这么顺利完成。
后续还有一些问题,有待进一步解决。
但无论如何,这场由物理位置上相隔千里万里,但始终在社区里朝夕与共的一群人密切配合来实施的大规模协同操作,取得最终的胜利。
因为我们团结在一起,我们必然胜利,我们也只能胜利。
此致
敬礼!
PlatON运营团队
2020年3月11日
附录:来自社区的意见建议精选及反馈
Wetez:判断磁盘空间这块可能会有一个极端情况,就是用户可能挂载多个磁盘,因为备份数据是会到data目录的上一层,data目录磁盘空间是够的,但可能上一级目录磁盘空间不够,导致备份失败。不过现在数据不大,基本不会有这种极限情况出现
回复:采纳并实施 - 很好的建议,已修改脚本
Epool:可否提供下编译镜像和运行镜像,dockerfile管理,自己已经搞了一个:PlatON-Node_Dockerfile/Dockerfile at master · zonzpoo/PlatON-Node_Dockerfile · GitHub
回复:采纳-好建议,我们后期持续优化和完善,考虑docker方式
Tushare:pid=ps -ef|grep platon|grep datadir|grep -v grep|awk '{print $2}'加grep-w可精确匹配
回复:采纳并实施 - 已进行修改
Tushare:这里很多用户不是root用户,很多命令可能需要sudo?
回复:采纳并实施 - 已进行修改
节点易:PlatON不是支持–config参数嘛,直接配置到文件,就不用那么长的命令了
回复:采纳 - 好建议,我们后期持续优化和完善
DolphinTwo:给脚本加个三点整校验的功能,就是到固定时间有输出,然后从3点到4点有log输出,证明脚本正常工作
回复:采纳并实施 - 已修改,直接每隔1分钟打一次屏
OG:./timer_restart.sh: 80: ./timer_restart.sh: Bad substitution
回复:采纳并实施 - 有效反馈,脚本问题已修改,spacetmp这个变量没有加$符
Epool:这个启动方式有问题吧,难道要一直连着服务器,一旦断了,脚本就断了。建议后面加个&
回复:采纳并实施 - 已修改为screen方式
IRISnet:old datadir value: ./data ./restart.sh: 80: ./restart.sh: Bad substitution用 sh ./restart.sh {datadir} 执行,脚本第一行 #!/bin/bash 不起作用,command=${command/$datadirTmp/$datadir} 会出如上错误,bash 或者直接 ./restart.sh 应该就没问题,目前已手动启动 platon 进程。
回复:采纳 - 环境兼容问题,后续优化
IRISnet:df -hBM $datadir|grep -v Filesystem,因为本地语言环境不同不一定是 Filesystem,可以换成 df -hBM /mnt/platon/ | tail -1 感觉好些!
回复:采纳 - 有效反馈,后续版本将优化
DolpinTwo:用sleep1s那精度是1秒,但是时间是根据date锚定的,每个机器的date可不一定一致,我们获取每个机器的date,然后转换成UTC时间,date如果不经常和ntp同步,就会有误差。
回复:采纳- 脚本后续需要优化,增加ntp同步